PyPI in the face: running jokes that PyPI download stats can play on you
Loïc Estève
![]()
@lesteve
![]()
![]()
About me
(apparently some strong theoretical bounds on cos/sin 😅)
![]()
![]()
![]()

![]()
PyPI in the face 🤔🥧?
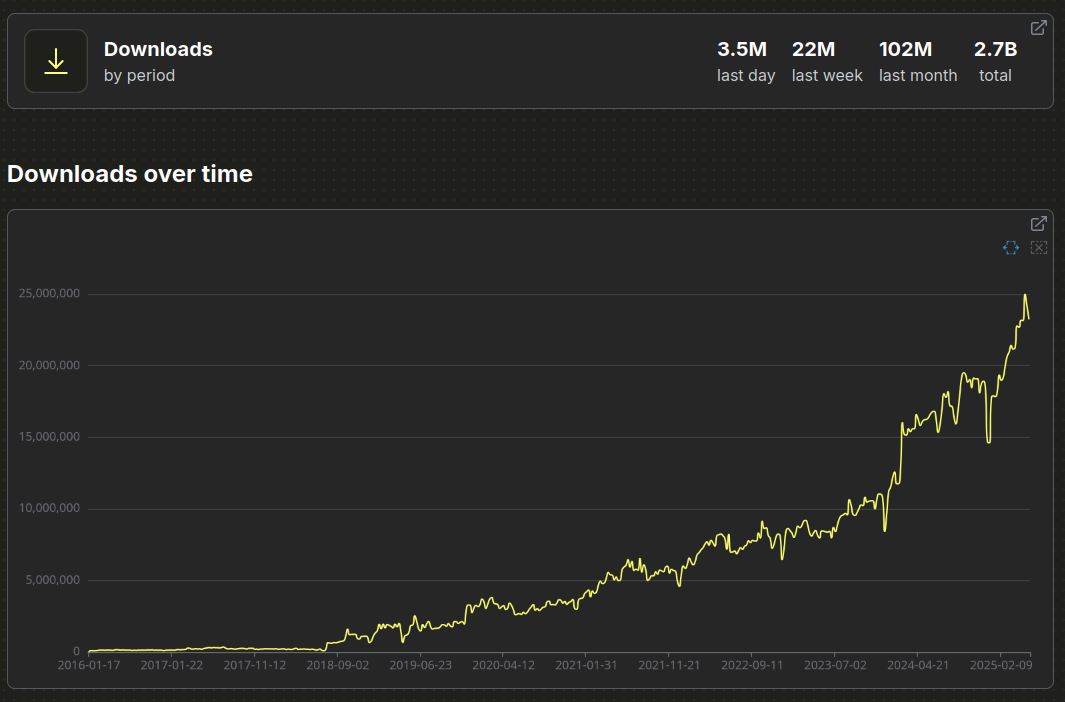
PyPI in the face 🤔🥧?



Google BigQuery PyPI dataset
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=pypi&page=dataset
Source of truth, historical bug until July 2018
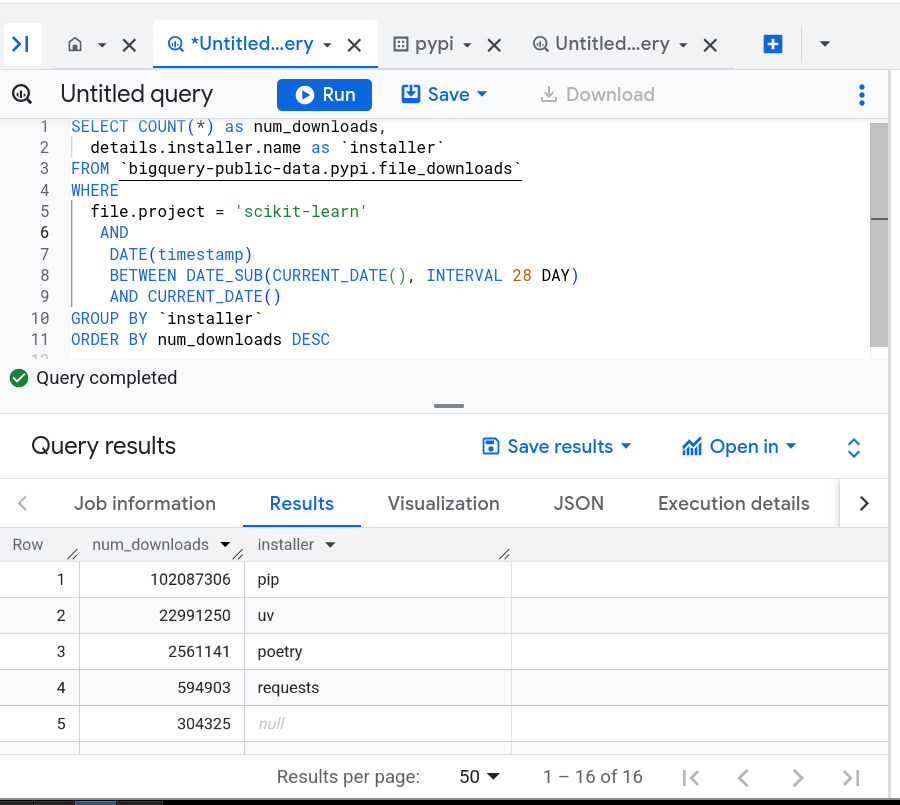
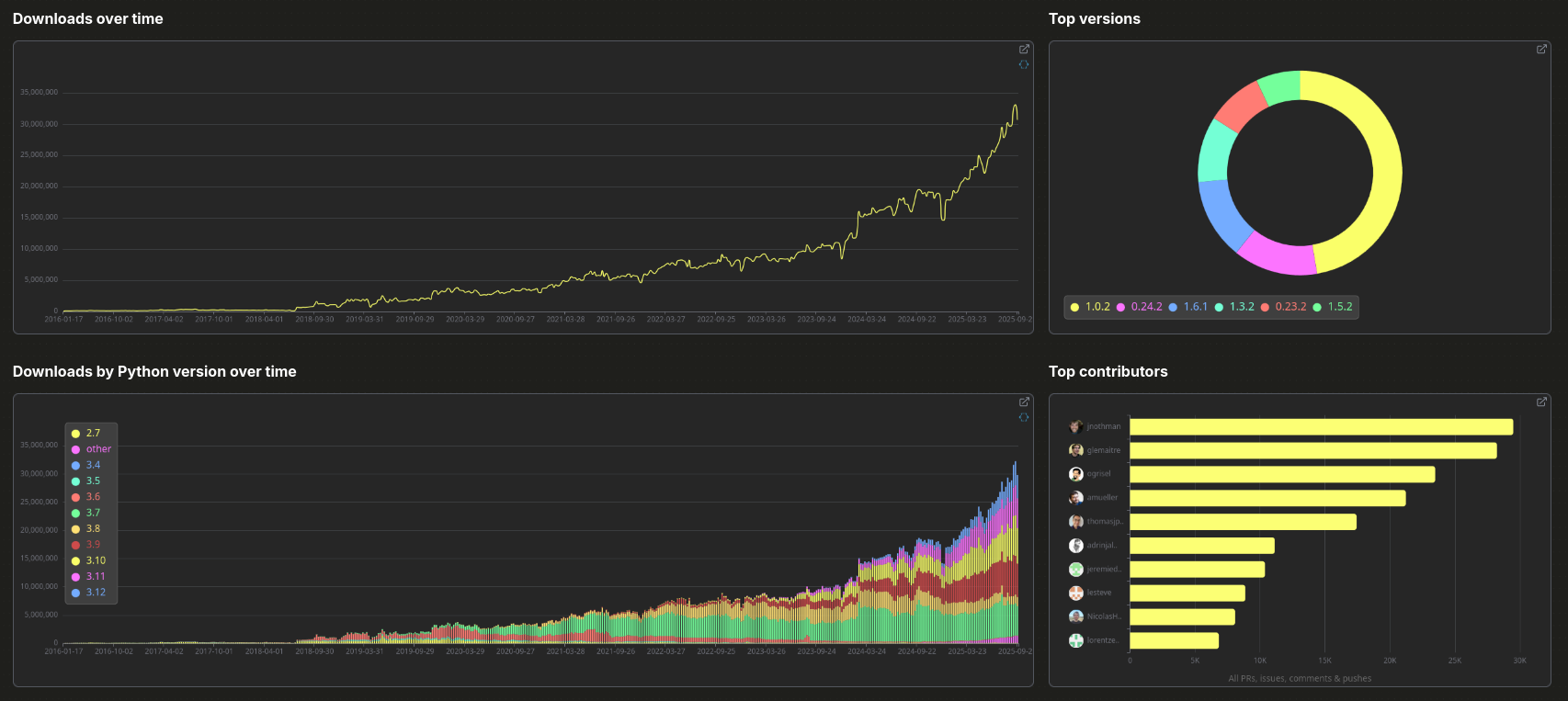
clickpy
clickpy: https://clickpy.clickhouse.com scikit-learn dashboard: https://clickpy.clickhouse.com/dashboard/scikit-learn
Copy and aggregation of the BigQuery DB. Historically there have been a few bugs so may want to double-check with Google BigQuery.
Can write your own SQL-like query to have more information
Open to change on their issue tracker (UI and “packages that needs refresh” wording)
maybe one day maybe: query + plots with Python using ibis on clickhouse DB
PyPI stats
PyPI stats: https://pypistats.org 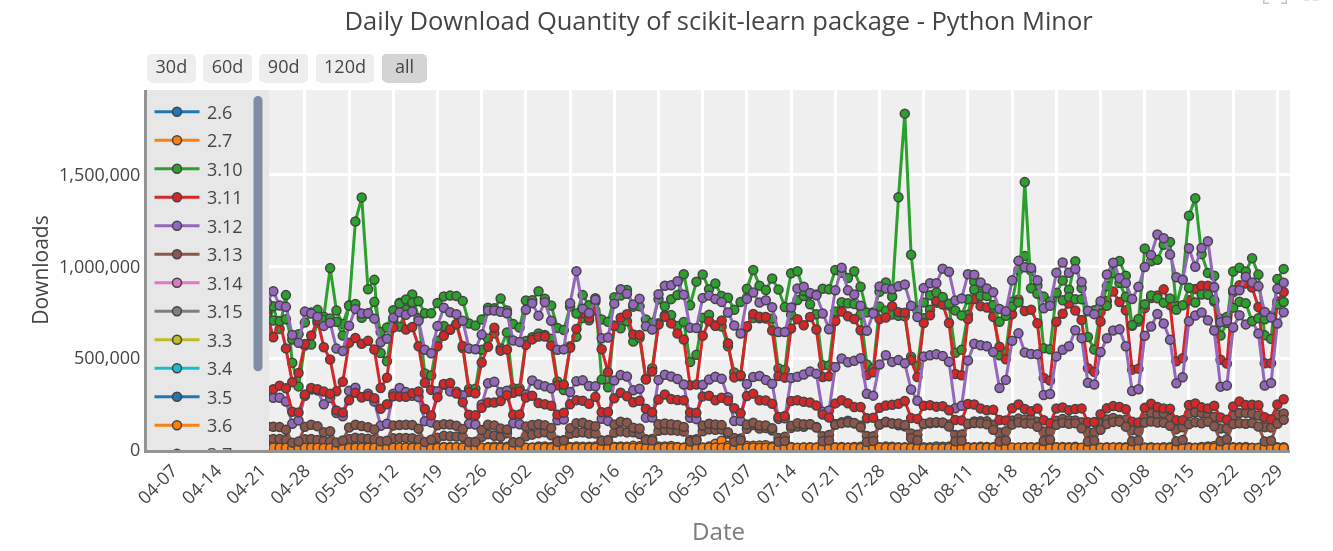
PSF has recently taken over the maintenance https://github.com/crflynn/pypistats.org/issues/82
Advantage: can tell with mirrors without mirrors only use pip in their aggregated numbers. No per-package version info.
Pepy
Pepy: https://pepy.tech avantage can look at different version.
Aggregate numbers use Paid option for longer timeline CI. Download numbers are inflated compared to pypistats.org (more info later)
skore
![]()
the scikit-learn sidekick https://github.com/probabl-ai/skore
Talk by Marie Sacksick “Enhancing ML workflows with skore” next (11:25) in Gaston Berger
Most downloads are from mirrors / something else than pip, uv etc …
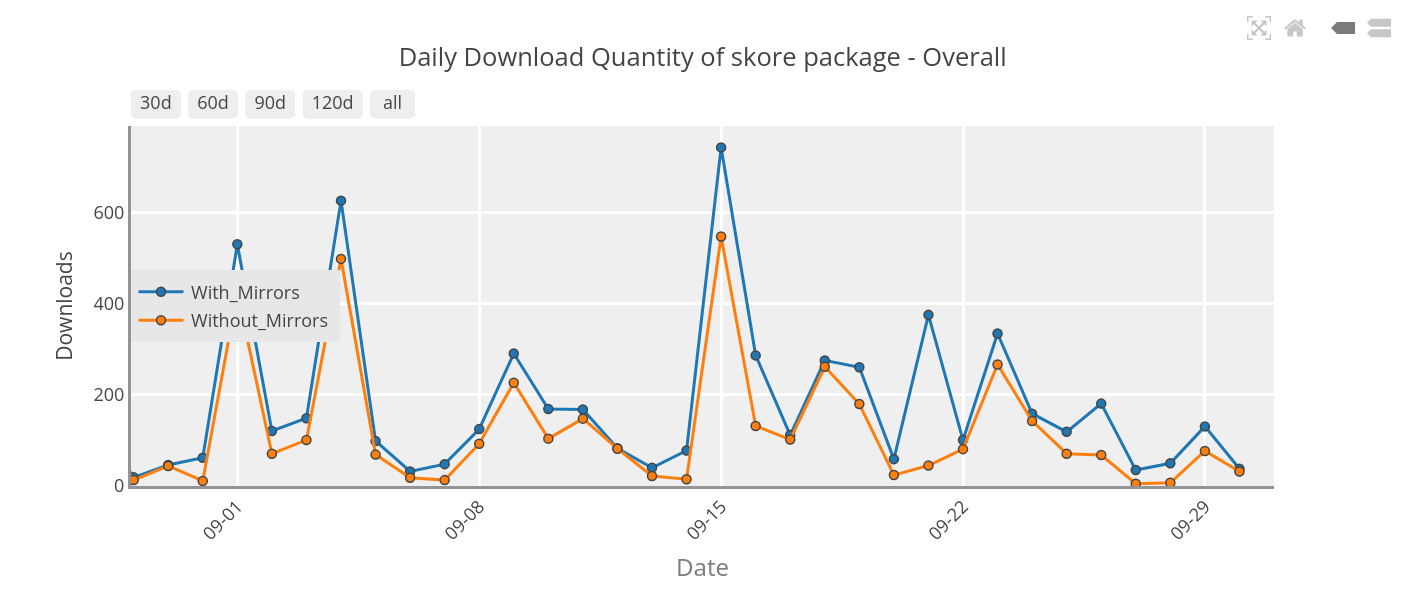
March 2025
| installer | downloads |
|---|---|
| bandersnatch | 771 |
| requests | 402 |
| uv | 336 |
| pip | 306 |
| Browser | 226 |
| NULL | 173 |
| … | … |
June 2025
| installer | downloads |
|---|---|
| pip | 1811 |
| uv | 814 |
| bandersnatch | 513 |
| NULL | 258 |
| Browser | 196 |
| requests | 78 |
| … | … |
installer type main source of discrepancy between different websites
pypistats.org only keep pip, others keep all installers
scikit-learn
website statistics: 1.2M unique visitors per month
PyPI download stats: ~100M per month
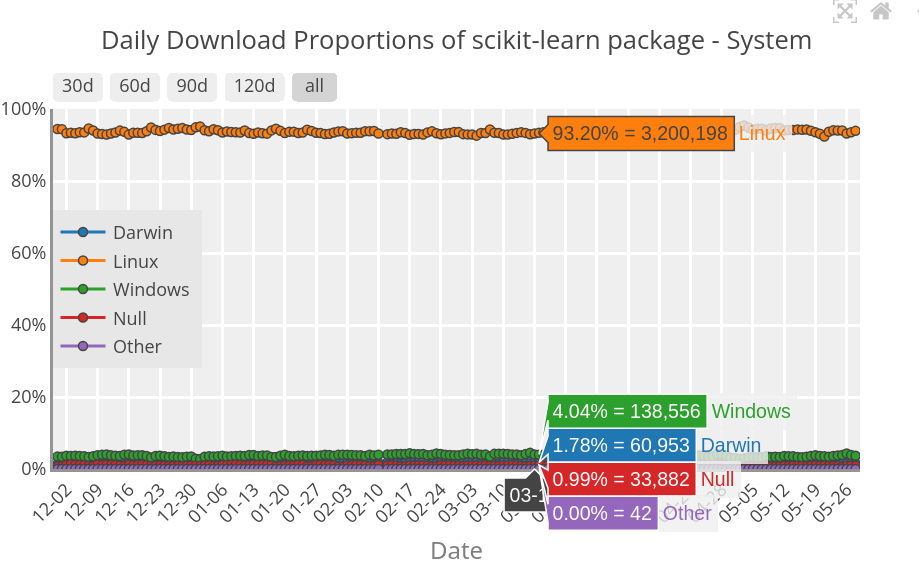
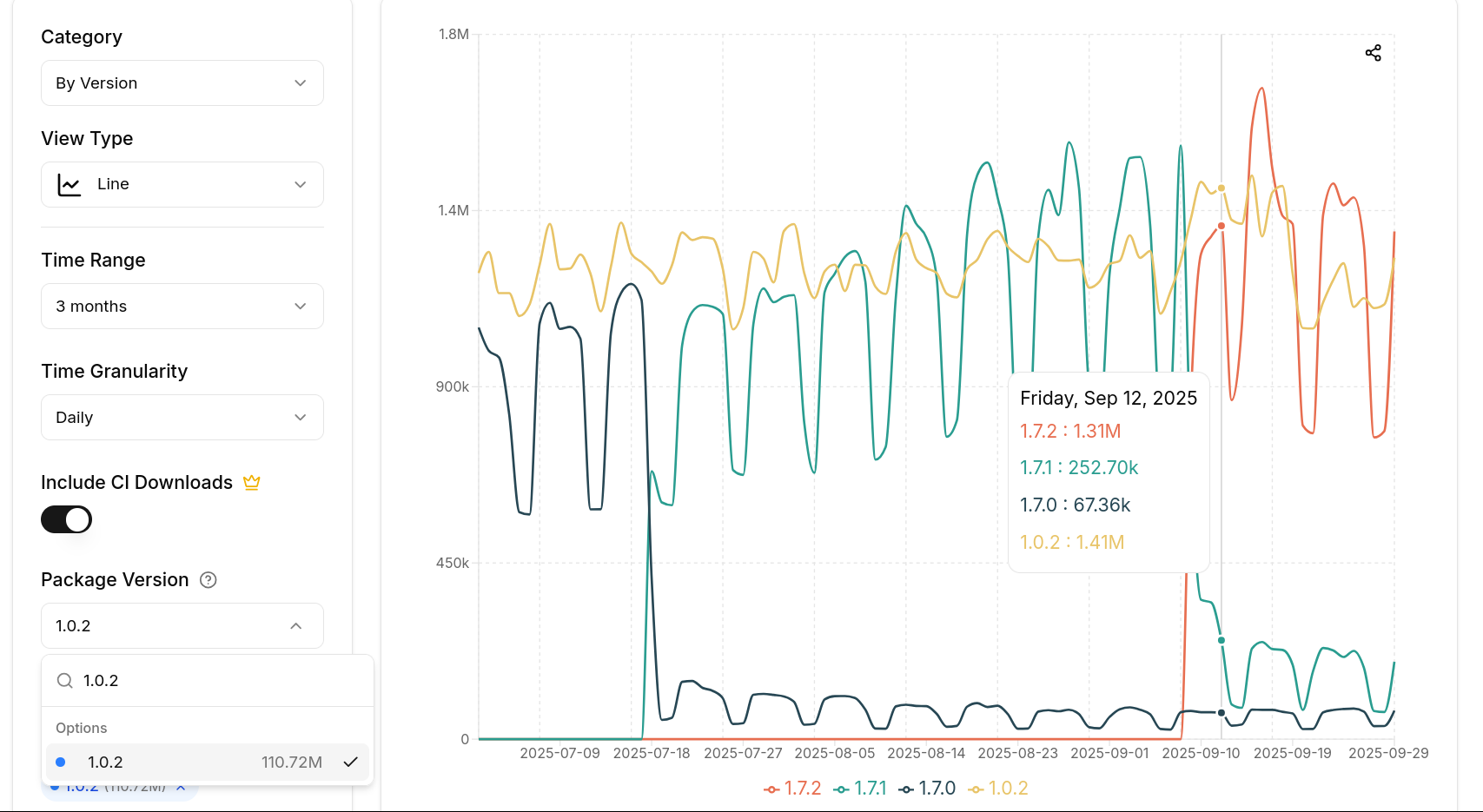
scikit-learn most downloaded release
Most downloaded scikit-learn release in 2025 is 1.0.2 released on 2021 Christmas day
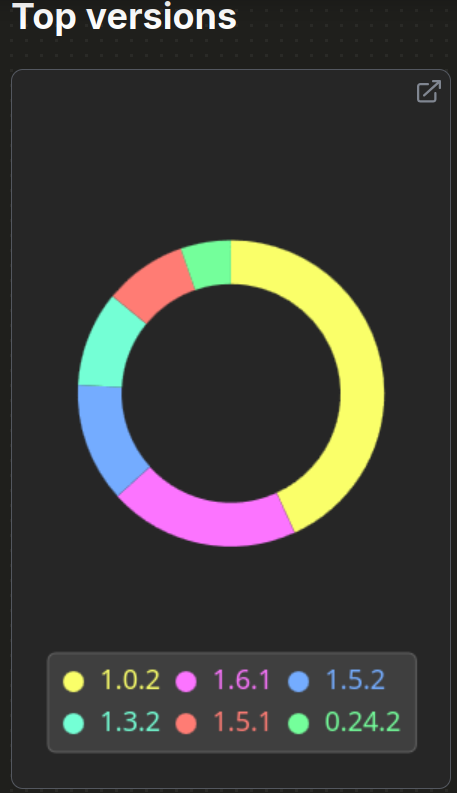
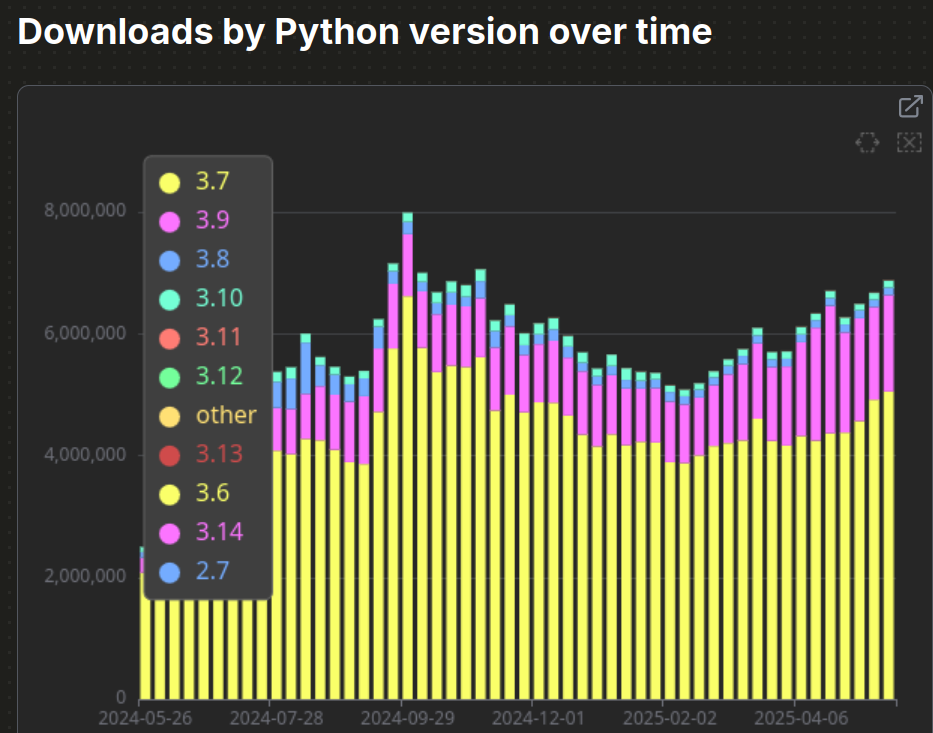
Reminder: Python 3.7 EOL 2023-06-27
scikit-learn dependencies: pip backtracking hypothesis
![]()
conda: joblib downloaded 1.2x more than scikit-learn
❯ condastats overall joblib scikit-learn scikit-learn --start_month 2025-03 --end_month 2025-07 --monthly
pkg_name time
joblib 2025-03 2275295
2025-04 2616275
2025-05 2266739
2025-06 2216331
2025-07 2170978
scikit-learn 2025-03 1930584
2025-04 2207607
2025-05 1908129
2025-06 1927962
2025-07 1845839
Exercise left to the reader: uv should show a similar pattern because has a better constraint solver?
sklearn data
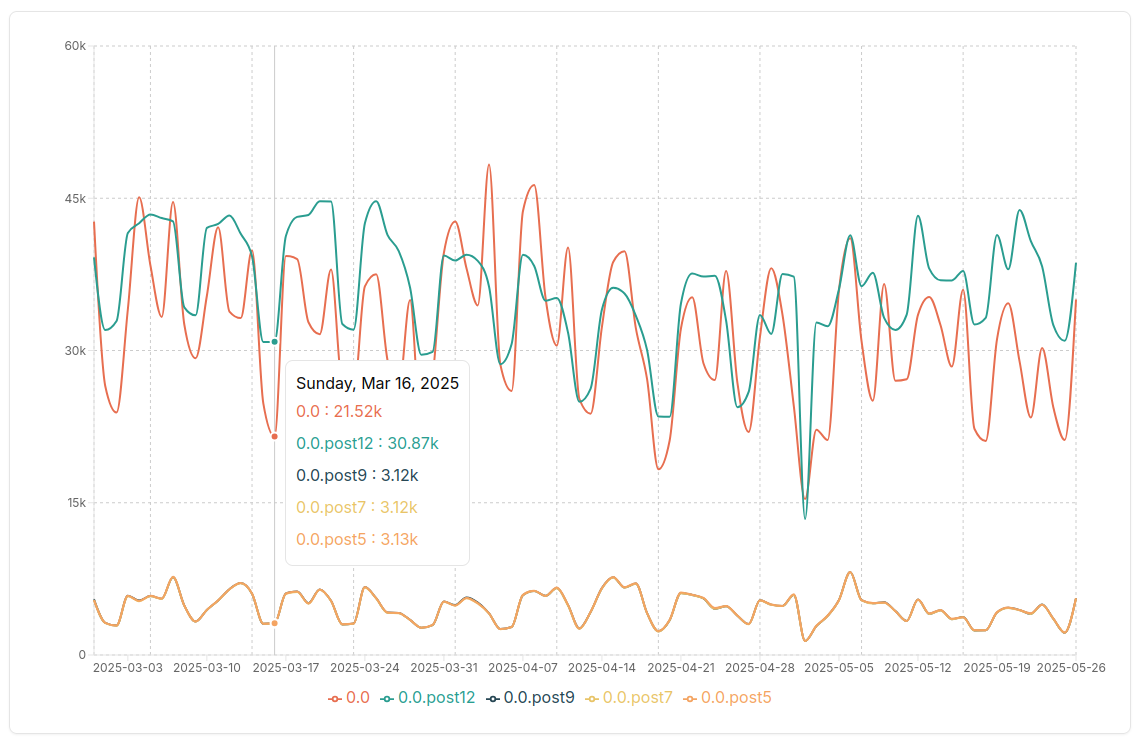
installer is mostly pip for 0.0.post5 and other transition releases, doen’t make much sense …
boto3 and friends
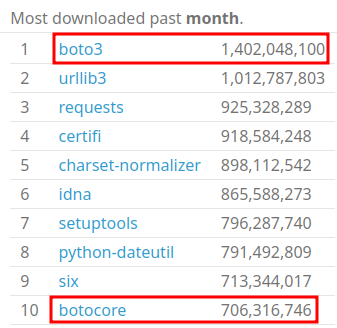
boto3 x.y.z depends on botocore>=x.y.z
new release almost every day
similar inversion pattern for other boto3 dependents: python-dateutil
botocore cached but not boto3 seems weird
In the end I know

But at least I tried a little bit 😅